

The specific syntax of Lisp dialects allows one to precisely define and distinguish basic constructs, add new syntactic elements, and even transform program code while it is running. This stems from the use of simple yet well-thought-out ways of organizing and representing source code.
Basic Constructs
Programs written in Lisp variants are characterized by simple syntactic rules. Rather than discussing them theoretically, we will begin with a practical example that we will refer back to in order to learn the basic mechanisms governing the translation of source code into a form understandable by a computer. By tracing what the compiler does, we will better understand the constructs of the language.
Here is our base example:
(print "Hello, Lisp!")
(print "Hello, Lisp!")
Not particularly difficult. Is it?
Syntax
Lisp looks like oatmeal with toenail clippings mixed in.
– Larry Wall
Let us start with syntax. The first thing that catches the eye when we see programs written in Lisp dialects is the placement of nearly every compound construct within parentheses. In other programming languages, parentheses serve to group selected syntactic elements, e.g., arguments when calling or defining a function, sets of conditions, or operations on values. In Lisps, parentheses are the fundamental lexical element used to give shape to the entire program and to every expression.
In Lisp-family languages we construct expressions using the so-called Polish notation (PN), also known as prefix notation. It consists of placing the operator (function name) first, followed by the operands (call arguments). Parentheses are used to mark the beginnings and ends of expressions.
Prefix notation differs from the infix notation popular in many programming languages, but not enough to make it very difficult to recognize the individual parts of expressions. Our sample program can be expressed in Ruby as follows:
print "Hello, Lisp!"
print "Hello, Lisp!"
And in C in the following way:
#include <stdio.h>
int main(int argc, char *argv[]) {
printf("Hello, Lisp!");
return 0;
}
#include <stdio.h>
int main(int argc, char *argv[]) {
printf("Hello, Lisp!");
return 0;
}
The differences between the discussed notations can be well illustrated with mathematical operations. Let us look at two simple computations:
2 + 2 * 3
2 + 2 * 3
And the notation conforming to Clojure syntax:
(+ 2 (* 2 3))
(+ 2 (* 2 3))
We can notice that in the second example the addition operator and its operands are enclosed in parentheses, and the name of the operation is always in the first position. An advantage of this notation is that there is no need to remember operator precedence.
Furthermore, in Polish notation, to represent more complex constructs in which we need to express containment relations, we do not need additional grouping markers (such as, e.g., curly braces or indentation) or separators (e.g., semicolons). Syntactic processing of expressions in prefix notation is simpler and faster because, owing to the more clearly defined structure, it requires fewer rules.
Reader
Let us return to our program:
(print "Hello, Lisp!")
(print "Hello, Lisp!")
The first stage of transforming its text into executable form is reading it into memory. In Lisps, the component responsible for this is called the reader. Its task is to open a file located on disk or an input stream associated with the user’s terminal and to subject the text being read to processing, in which we can distinguish two main phases:
-
detecting known lexical constructs in the text;
-
extracting grammatically correct expressions from the detected constructs and representing them as internal, in-memory structures.
Lexical analysis
The first phase of reading program sources into memory is lexical analysis. It consists of:
-
cleaning the input of unnecessary symbols;
-
recognizing in the character stream sequences matching the lexical units defined in the language lexicon, in this context called tokens;
-
extracting from the text fragments that have syntactic significance (so-called lexemes), which are a kind of instances of the detected tokens.
The result of lexical analysis applied to our example will be a stream of lexemes – that is, extracted fragments of the program text that have syntactic significance:
| Lexeme | Token name |
|---|---|
( |
list literal (opening) |
print |
symbol |
"Hello, Lisp!" |
string literal |
) |
list literal (closing) |
During the described process (called tokenization) the extracted lexemes may optionally be annotated with information about their corresponding tokens, so that this task does not need to be repeated during subsequent analyses.
Because of the specific syntax of Clojure (similarly to other Lisp dialects), lexical analysis is greatly simplified and often amounts to passing control to the parser as soon as a lexeme is found.
Syntactic analysis
The second phase of processing source code into an in-memory form is syntactic analysis, also called parsing. It encompasses:
-
recognizing syntactic constructs in the stream of lexemes by comparing their kinds and positions against the grammatical rules of the language;
-
extracting expressions – that is, grammatical constructs whose values can be computed in later compilation stages;
-
producing in-memory representations of the found expressions using appropriate data structures;
-
placing the resulting objects in the abstract syntax tree (AST).
The result of syntactic analysis is the representation of the program’s source code in memory accessible to the compiler.
Reader forms
Reader forms is a term used in Clojure to describe lexical units used to build grammatically correct syntactic constructs.
The table below lists the basic reader forms. The first column contains the token name, the second column shows example lexemes, and the last column indicates the data type of the in-memory object that will represent the lexemes in the abstract syntax tree, provided grammatical requirements are met.
| Token name | Example lexemes | Data type |
|---|---|---|
| symbol | onespace/two |
Symbol |
| nil literal | nil |
nil |
| keyword literal | :one::two:space/x::space/y |
Keyword |
| string literal | "one two" |
java.lang.String |
| list literal | (1 2 3) |
PersistentList |
| vector literal | [1 2 3] |
PersistentVector |
| map literal | {:a 1 :b 2}::{:a 1 :b2}:space{:a 1 :b 2} |
PersistentArrayMapPersistentHashMap |
| boolean literal | true, false |
java.lang.Boolean |
| integer literal | 10xff0172r1101 |
java.lang.Long |
| rational literal | 1/2 |
Ratio |
| big number literal | 1.2M1N |
java.math.BigDecimalBigint |
| float literal | -2.7e-4 |
java.lang.Double |
Reader macros
In Clojure, some syntactic constructs are implemented as so-called reader macros. These are also subroutines responsible for processing lexical units, but implemented somewhat differently. Instead of being hardcoded into the reader’s rule set, they reside in a special read table, where specific tokens are assigned to the subroutines responsible for their analysis.
In Clojure, the programmer cannot modify the read table, and there are no indications that such a capability is planned for the future. The motivation is to maintain a unified syntax across projects of diverse origin. However, we can use so-called tagged literals, which resemble reader macros, although they are subject to certain syntactic constraints.
The following table presents reader macros:
| Token name | Example lexemes | Data type |
|---|---|---|
| quoting (quote) | 'one'(one two) |
varies |
| syntax quoting (syntax-quote) |
`one`(two three) |
varies |
| syntax unquoting (syntax unquote) |
~quote |
varies |
| syntax unquoting with splicing (syntax unquote-splicing) |
~@(list 1 2) |
varies |
| metadata map (metadata map) |
^{:doc "Description"} |
PersistentArrayMapPersistentHashMap |
| metadata key (metadata key) |
^:dynamic true |
PersistentArrayMapPersistentHashMap |
| metadata tag (metadata tag) |
^Integer x |
PersistentArrayMapPersistentHashMap |
| comment (comment) |
; comment |
none |
| character literal (character literal) |
\a, \b, \c, \newline |
java.lang.Character |
| dereference expression (dereference expression) |
@x |
java.lang.Class (with IFn) |
| Java member-access operator (Java member-access operator) |
(. " a " trim)(.trim " a ") |
varies |
| Java member-access operators (Java member-access operators) |
(.. "a" trim length) |
varies |
| dispatch macro (dispatch macro) | #… |
varies |
The last entry in the table is the so-called dispatch macro. This is a general term
for a subgroup of reader macros whose tokens all begin with the hash symbol (#).
When the reader encounters this character, it passes control over further analysis of
the construct to a separate macro table. Below is a list of tokens handled using the
dispatch macro:
| Token name | Example lexemes | Data type |
|---|---|---|
| Var quoting (var-quote) |
#'x |
Var |
| set literal (set literal) |
#{1 2 3} |
PersistentHashSet |
| regular expression (regular expression) |
#"one.tw[oO]" |
java.util.regex.Pattern |
| anonymous function literal (anonymous function literal) |
#(pr) |
java.lang.Class (with IFn) |
| anonymous function argument (anonymous function argument) |
#(pr %)#(pr %1 %2) |
PersistentTreeMap |
| ignore next form (ignore next form) |
#_ one two |
none |
| Java constructor call (Java constructor call) |
#name.type[:x]#name.record{:x 1} |
varies |
| reader conditional (reader conditional) |
$?(:clj "Clojure":cljs "ClojureScript") |
varies |
| tagged literal (tagged literal) |
#symbol argument |
varies |
inst tagged literal( inst tagged literal) |
#inst "2018-11-12" |
java.util.Date |
UUID tagged literal( UUID tagged literal) |
#uuid "88b05082-392d-4e0a-89c9-cf62ec375c43" |
java.util.UUID |
Note that some lexical units will not be represented by objects of a predetermined data type (marked “varies” in the type column). For example, quoting itself is not associated with producing a particular structure, but influences how a given construct is further parsed. We will also find tokens that do not cause any value to be generated (“none” in the type column), because they selectively exclude certain elements of the program text from the syntactic analysis process.
Also noteworthy is the type java.lang.Class with the annotation “with IFn”. This
notation indicates that in Clojure, function objects are expressed by anonymous Java
classes equipped with the IFn interface. This is related to the characteristics of
functions in Java – they do not have properties that would allow using them directly.
S-expressions
At the grammatical level, every element of source code in Lisp is a symbolically written expression. The textual representations of expressions – those we see in an editor – are called symbolic expressions, abbreviated as S-expressions (sexprs, sexps).
The structure of S-expressions somewhat resembles XML or JSON – that is, we are dealing with a notation that allows expressing nested and ordered sets of values, though in a somewhat simpler way than the aforementioned formats.
An S-expression in Lisp can be defined as a kind of notation in which:
- every element is an expression:
- non-compound (called an atom) or
- composed of S-expressions enclosed in parentheses and separated by a separator.
print ; atomic S-expression (not a list of S-expressions)
"Hello, Lisp!" ; atomic S-expression (not a list of S-expressions)
(print "Hello, Lisp!") ; list S-expression
() ; both list and atomic S-expression
(print (+ 2 2)) ; S-expression composed of nested S-expressions
print ; atomic S-expression (not a list of S-expressions)
"Hello, Lisp!" ; atomic S-expression (not a list of S-expressions)
(print "Hello, Lisp!") ; list S-expression
() ; both list and atomic S-expression
(print (+ 2 2)) ; S-expression composed of nested S-expressions
An S-expression in Clojure will be defined in a somewhat richer way, because we have additional collection literals there. It will be a kind of notation in which:
- every element is an expression:
- non-compound (called an atom) or
- composed of separated S-expressions:
- in pairs, enclosed in curly braces –
{...}; - individually, enclosed in:
- round parentheses –
(...); - curly braces with a hash symbol –
#{...}; - square brackets –
[...].
- round parentheses –
- in pairs, enclosed in curly braces –
In the case of expressions in curly braces, the first elements of pairs must be unique values within the entire expression, and in the case of expressions in curly braces preceded by a hash symbol, each value must be unique. This check is performed already during syntactic analysis, and when a given element requires prior computation, during evaluation.
:one ; atomic S-expression
1 ; atomic S-expression
print ; atomic S-expression
"Hello, Lisp!" ; atomic S-expression
(print "Hello, Lisp!") ; list S-expression
[1 2 3] ; vector S-expression
#{1 2 3} ; set S-expression
{:one 1 :two 2 :three 3} ; map S-expression
(str [1 2 3]) ; list and vector S-expressions
:one ; atomic S-expression
1 ; atomic S-expression
print ; atomic S-expression
"Hello, Lisp!" ; atomic S-expression
(print "Hello, Lisp!") ; list S-expression
[1 2 3] ; vector S-expression
#{1 2 3} ; set S-expression
{:one 1 :two 2 :three 3} ; map S-expression
(str [1 2 3]) ; list and vector S-expressions
The recursive definition of an S-expression may seem difficult to understand, so we will aid ourselves with our one-line program and perform a manual categorization of the elements present in it.
In the notation (print "Hello, Lisp!"):
(...)is an S-expression, because it is a symbolically written list of S-expressions;printis an S-expression, because it is an atom;"Hello, Lisp!"is an S-expression, because it is an atom.
Graphically, this set can be presented as follows:
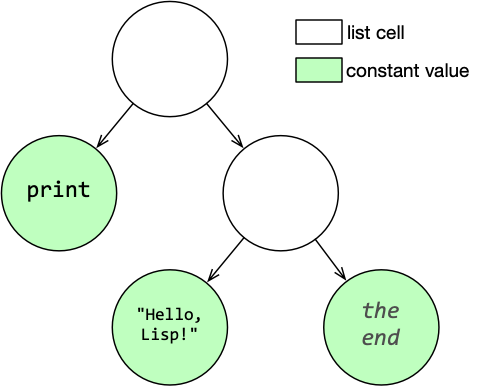
Unlike other Lisps, compound S-expressions in Clojure are built not only from lists marked by round parentheses, but also using additional markers that correspond to certain kinds of collections. Depending on the notation used, a data structure representing the appropriate kind of S-expression will be created in memory:
| Notation | Literal | S-expression | Structure | Data type |
|---|---|---|---|---|
(a...z) |
list | list | list | PersistentList |
[a...z] |
vector | vector | vector | PersistentVector |
{a b ... x y} |
map | map | map | PersistentArrayMapPersistentHashMap |
#{a...z} |
set | set | set | PersistentHashSet |
Atoms
When discussing symbolic expressions, we mentioned a specific class of them called atoms. An atom is an element of Lisp syntax that is not compound (is not: a list, a set, a vector, or a map). The exceptions are the empty list, the empty set, the empty vector, and the empty map, which are both compound expressions and atoms.
However, one more important condition must be added to the above definition, a condition that determines whether a symbolic notation can be considered a Lisp atom. Let us recall our program:
(print "Hello, Lisp!")
(print "Hello, Lisp!")
In the previous examples, we could see that print and Hello, Lisp! are atoms, but
would any arbitrary set of characters that is not a pair of parentheses with content
qualify? No. An atom must be a valid syntactic construct on the basis of which the
reader will be able to decide what object to place in the AST. There is a certain
rigor here. In this particular case, the text print will be stored as a symbol, and
Hello, Lisp! as a string, because they satisfy the syntactic requirements for
representing specific data structures.
Admittedly, the syntactic rules are liberal enough that most randomly typed words or even single characters will be recognized as symbols (and thus atoms), but placing a parenthesis in a symbolic label or starting it with a digit would be serious violations, and the reader would stop cooperating with us.
It is worth noting that the concept of an atom as a class of syntactic expressions is not widely used among Clojure programmers. This is probably because in Clojure there exists a reference data type called Atom which helps perform concurrent data operations.
List S-expressions
The most commonly encountered class of S-expressions are list S-expressions. It is thanks to them that programs written in Lisp dialects consist of a large number of parentheses.
A list S-expression in Clojure should be a list of elements (other S-expressions) separated by spaces, commas, or both. The beginning and end of a list S-expression should be marked by an opening and closing round parenthesis.
List expressions with symbols placed in their first positions serve to invoke subroutines (functions, macros, or special constructs) identified by them. The remaining elements of the list then express arguments passed to the invocation. In the case of functions, argument values will be computed before being applied.
If no elements are provided, a list S-expression will produce an empty list.
1;; calling the + function
2
3(+ 1 2 3)
4;=> 6
5
6;; calling the defn macro
7;; used to define a named function
8
9(defn greet [] "Hello!")
10;=> #'user/greet
11
12;; calling the defined greet function
13
14(greet)
15;=> "Hello!"
16
17;; special form def
18;; used to define a global variable
19
20(def x 2)
21;=> #'user/x
22
23;; doubling the value of the global variable
24;; identified by the symbol x
25
26(+ x x)
27;=> 4
28
29;; empty list
30
31()
32;=> ()
;; calling the + function
(+ 1 2 3)
;=> 6
;; calling the defn macro
;; used to define a named function
(defn greet [] "Hello!")
;=> #'user/greet
;; calling the defined greet function
(greet)
;=> "Hello!"
;; special form def
;; used to define a global variable
(def x 2)
;=> #'user/x
;; doubling the value of the global variable
;; identified by the symbol x
(+ x x)
;=> 4
;; empty list
()
;=> ()
Older Lisp dialects supported a somewhat different form of list S-expressions. Inside
a pair of parentheses one did not place a list of all elements, but only one cell of
the list, divided into a left and right value separated by a dot, with the end of the
list marked by the symbol nil, e.g.:
(+ . (1 . (2 . nil)))
(+ . (1 . (2 . nil)))
In Clojure, this kind of notation is not supported, although there are data structures that allow performing operations on individual cells and creating so-called sequences.
Vector S-expressions
Vector literals create so-called vector S-expressions, but unlike list expressions, elements placed in their first positions have no special significance. The result of using a vector S-expression in its basic form will be a data structure called a vector, and each of its elements will become a component of it after its value has been computed.
Using vector S-expressions we can:
-
create the aforementioned vectors and use them for application logic,
-
specify argument lists of defined functions and macros,
-
express bindings of symbols to values in appropriate special constructs (including
letandbinding), -
perform so-called positional destructuring of compound structures with a sequential access interface.
;; literal vector
[1 2 3 4]
;=> [1 2 3 4]
;; literal vector
[(+ 1 1) 2 3 4]
;=> [1 2 3 4]
;; bindings vector in a let form
;; creates a lexical binding of symbol a to value 1
(let [a 1] a)
;=> 1
;; vector binding form in a let form (destructuring)
;; inside the bindings vector of the let form
;; binds each symbol from the S-expression [a b]
;; to an initializing value from the S-expression [1 2]
;; according to position
(let [[a b] [1 2]]
(+ a b))
;=> 3
;; argument list in a named function definition
(defn add
[a b]
(+ a b))
(add 2 2)
;=> 4
;; empty vector
[]
;=> []
;; literal vector
[1 2 3 4]
;=> [1 2 3 4]
;; literal vector
[(+ 1 1) 2 3 4]
;=> [1 2 3 4]
;; bindings vector in a let form
;; creates a lexical binding of symbol a to value 1
(let [a 1] a)
;=> 1
;; vector binding form in a let form (destructuring)
;; inside the bindings vector of the let form
;; binds each symbol from the S-expression [a b]
;; to an initializing value from the S-expression [1 2]
;; according to position
(let [[a b] [1 2]]
(+ a b))
;=> 3
;; argument list in a named function definition
(defn add
[a b]
(+ a b))
(add 2 2)
;=> 4
;; empty vector
[]
;=> []
Map S-expressions
Using the map literal we can construct map S-expressions. In their basic form they allow expressing an associative data structure called a map, which consists of indexed key–value pairs. Values should be separated by spaces, commas, or both. The first element of each pair is called the key, and the second the value.
Using map S-expressions we can:
-
create the aforementioned maps and use them for application logic,
-
specify named argument lists of defined functions and macros,
-
construct so-called metadata maps that allow enriching certain constructs with metadata that can describe them or control their properties;
-
perform associative destructuring of compound structures with an associative access interface.
;; literal map
{"a" 1 "b" 2}
;=> {"a" 1 "b" 2}
;; map expressing named arguments
;; of a defined function
;; keys a and b must be strings
(defn add [& {:strs [a b]}]
(+ a b))
;; calling a function with named arguments
(add "b" 1, "a" 3)
;=> 4
;; metadata map of a defined function
;; with a documentation string (key :doc)
(defn add
{:doc "This function adds two numbers."}
[a b]
(+ a b))
;=> #'user/add
;; calling the documentation string for add
(doc add)
;=>> -------------------------
;=>> user/add
;=>> ([a b])
;=>> This function adds two numbers.
;=> nil
;; map binding form in a let form (destructuring)
;; inside the bindings vector of the let form
;; binds symbols a and b
;; to values from a map indexed by "a" and "b"
(let [{:strs [a b]} {"b" 1 "a" 3}]
(+ a b))
;=> 4
;; empty map
{}
;=> {}
;; literal map
{"a" 1 "b" 2}
;=> {"a" 1 "b" 2}
;; map expressing named arguments
;; of a defined function
;; keys a and b must be strings
(defn add [& {:strs [a b]}]
(+ a b))
;; calling a function with named arguments
(add "b" 1, "a" 3)
;=> 4
;; metadata map of a defined function
;; with a documentation string (key :doc)
(defn add
{:doc "This function adds two numbers."}
[a b]
(+ a b))
;=> #'user/add
;; calling the documentation string for add
(doc add)
;=>> -------------------------
;=>> user/add
;=>> ([a b])
;=>> This function adds two numbers.
;=> nil
;; map binding form in a let form (destructuring)
;; inside the bindings vector of the let form
;; binds symbols a and b
;; to values from a map indexed by "a" and "b"
(let [{:strs [a b]} {"b" 1 "a" 3}]
(+ a b))
;=> 4
;; empty map
{}
;=> {}
Set S-expressions
The set literal enables writing set S-expressions. Thanks to them, one can express sets in a clear and straightforward way – that is, structures in which each element appears only once.
The set literal consists of curly braces preceded by a hash symbol, inside which unique-within-the-set values are placed. Elements of a set S-expression should be separated by a space, a comma, or both.
If an element of a set expression is not a constant value, it will be computed before the object representing the set is created.
#{1 2 3 4}
;=> #{1 2 3 4}
#{1 (+ 1 1) 3 4}
;=> #{1 2 3 4}
;; empty set
#{}
;=> #{}
#{1 2 3 4}
;=> #{1 2 3 4}
#{1 (+ 1 1) 3 4}
;=> #{1 2 3 4}
;; empty set
#{}
;=> #{}
Abstract syntax tree
We know that the result of syntactic analysis is a form of source code in the abstract syntax tree. Let us see what it will look like after reading our program:
(print "Hello, Lisp!")
(print "Hello, Lisp!")
The opening parenthesis at the beginning will cause the reader’s mechanisms to treat the lexical construct as a list literal. Taking the content into account, it will form a grammatical construct: a list S-expression. During the parsing phase it will be transformed into a list object – that is, a structure used to store an ordered set of data. These data will be the representations of the two atomic S-expressions placed within the parentheses:
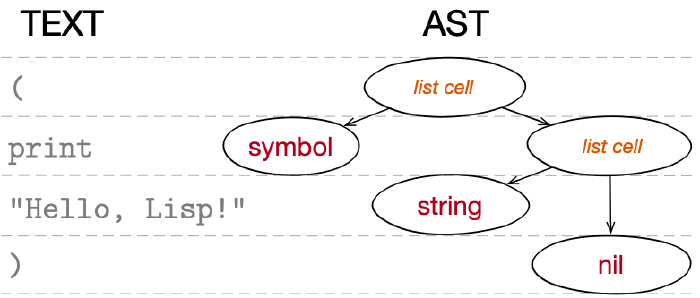
The syntax tree is not an element specific to Lisps. Compilers and interpreters of other programming languages also use it. However, in their case the AST is partially or entirely inaccessible to the programmer and built using internal data structures that are not supported by the language. Operating on the syntax tree from within the program is either impossible or limited to using special macro mini-languages. In Lisps, things are different, as we will learn later.
Returning to our program… The first element of the list S-expression is the atom
print. It will be recognized as another known syntactic element: a symbol. The
rules of the language state that it must be a word composed of alphanumeric characters
that does not begin with a digit or with a special character indicating data of
a different kind. In the in-memory list structure, an object of type
Symbol will be placed at the first position. This data type resembles
keywords or text labels known from other languages – it will be discussed more broadly
in a later section.
The last component of the symbolic expression we entered is the string literal
Hello, Lisp!, which can be detected by the quotation marks surrounding the text. It
too is an atom and will be treated as a representation of a string, which will be
placed at the end of the list residing in the syntax tree.
To summarize, in the AST the following will be created:
- a data structure (list) consisting of:
- a datum of type symbol,
- a datum of type string.
Let us notice that the graphical representation of source code in the abstract syntax tree and the earlier-shown way of organizing S-expressions are similar to each other. Coincidence?
Homoiconicity
In Lisps, the in-memory AST objects are represented using the same data structures that we can use in programs. Moreover, their arrangement in the syntax tree is the same as the layout of S-expressions in the textual representation. In other words: the abstract syntax tree and the program text are isomorphic. If necessary, we can read the AST and obtain readable source code in the form of symbolic expressions.
The trait described here is called homoiconicity and opens the possibility of transforming S-expressions reflected in the AST using the system of syntactic macros, to which a separate chapter will be devoted.
Semantics
The next important stage of transforming a program into executable form is semantic analysis – that is, the process of recognizing the meaning-bearing constructs of the language. In Lisp dialects, this is one of the first tasks of the component called the evaluator. It consists of reading the objects of the abstract syntax tree representing expressions, checking whether they are semantically correct, and computing the value of each one by running the appropriate subroutines. In the case of Clojure, part of this process will be carried out during compilation, and part at program runtime.
Let us recall our example once more:
(print "Hello, Lisp!")
(print "Hello, Lisp!")
After reading the source code into memory, data representing it were placed in the AST, and during program execution, each datum will be evaluated in order to ultimately obtain the value of the outermost S-expression.
In the given example, the first element of the list is the symbol print, which
identifies a built-in Clojure function used to display text on the screen. By
examining the current namespace, the compiler will find the appropriate
mapping of the symbol to a function object and determine that it is
dealing with a construct that is a function call. It will also identify the
subroutine that needs to be invoked to perform the operation.
Functions can accept arguments, and the given symbolic expression also contains (apart
from the operation name) an argument intended for its call. Because in Lisps we are
dealing with pass-by-value, the process of evaluating the string Hello, Lisp! will
be performed first. A string is a constant value, so no further computation will be
required, and it is this value that will be passed to the call.
Running the print function subroutine will produce the intended side effect of
displaying the following on screen:
Hello, Lisp!
Additionally, the function will return a value that, depending on how the program was launched, will be displayed (in the case of an interactive console) or remain unhandled (in other cases).
Forms
The abstract syntax tree in Lisps is data organized as nested lists. Each such datum is a Lisp form, called simply a form – that is, an in-memory representation of a syntactically valid S-expression intended for evaluation.
The evaluator, analyzing AST elements, attempts to compute their values, paying attention to data types and the contexts in which they appear. Several main decision paths of the evaluating subroutine are possible, corresponding to different kinds of forms encountered.
By examining only the data structures in the AST or the S-expressions in the source
code text, we cannot precisely determine what specific form we will be dealing
with. This can only be established during evaluation. For example, the symbol x
placed at the first position of the list S-expression (x 1) may, after evaluation,
turn into a function object – and then it will be a function-call form for x – but
it may also turn out to be, say, a map, and then it will be a map lookup form where
the value 1 is treated as a key.
Before we proceed to discussing the main kinds of forms, let us name those that will be recognized in our program:
(print "Hello, Lisp!")
(print "Hello, Lisp!")
(...)– compound form,print– symbol form,"Hello, Lisp!"– normal form,(print "Hello, Lisp!")– function-call form:- after detecting that
printis bound to a function; - after detecting the function’s argument form;
- after computing the argument to a normal form.
- after detecting that
Constant and normal forms
A source code expression representing a constant value that does not require computation will be recognized by the evaluator as a so-called constant form and passed unchanged to the calling, parent construct.
The most direct kind of constant form is the so-called normal form – a source code datum that by its nature does not require evaluation, because it is already represented in the syntax tree by its own value. Examples include numeric literals and string literals.
"Hello, Lisp!" ; string
\a ; character
() ; empty list
123 ; integer
'lalala ; quoted symbol
"Hello, Lisp!" ; string
\a ; character
() ; empty list
123 ; integer
'lalala ; quoted symbol
An interesting kind of constant form is the result of applying the quote form –
a special syntactic form that allows disabling evaluation of the S-expressions passed
to it and treating the source code data as constant structures. The quote construct
and the quoting mechanism will be discussed in more detail further on.
Symbol forms
A symbol will be treated by the evaluator as a symbol form, and it will attempt to find the object bound to it, which – depending on the context – may be assigned to that symbol’s name in various places, e.g., in lexical bindings or namespaces (and global variables). The obtained value will be substituted in place of the symbol’s occurrence.
print
+
print
+
See also:
- “Symbol forms”, chapter IV.
Compound forms
When the evaluator encounters a non-empty collection, it will recognize it as a so-called compound form.
In the case of a map form, a vector form, or a set form, each element will be evaluated, and a collection will be returned in which every element has been computed to a constant form.
[1 2 3] ; vector form
#{1 2 3} ; set form
{"a" 1 "b" 2} ; map form
'(1 2 3) ; list form (literal list)
[1 2 3] ; vector form
#{1 2 3} ; set form
{"a" 1 "b" 2} ; map form
'(1 2 3) ; list form (literal list)
In the case of a list or a sequence of Cons objects, the value of
the first element will be computed, and a decision will be made regarding the further
course of action depending on the detected form.
Lookup forms
If the first element of a list form being evaluated is a vector, a set, or a map, then a vector lookup form, a set lookup form, or a map lookup form will be recognized, respectively. The value of the next element in the list will be passed as an argument to the subroutine responsible for finding elements by given indices. If there are more arguments, an error will be generated.
([1 2 3] 0) ;=> 1
(#{1 2 3} 2) ;=> 2
({"a" 1 "b" 2} "b") ;=> 2
([1 2 3] 0) ;=> 1
(#{1 2 3} 2) ;=> 2
({"a" 1 "b" 2} "b") ;=> 2
If the first element of a list form being evaluated is a keyword or a literal symbol, then a keyword lookup form or a symbol lookup form will be recognized, and the value of the next element in the list will be passed as an argument to a subroutine that uses the given keyword or symbol as an index to find the value. If there are more arguments, an error will be generated.
(:a {:a 1 :b 2}) ;=> 1
(:a #{:a :b :c}) ;=> :a
('a {'a 1 'b 2 :c 3}) ;=> 1
(:a {:a 1 :b 2}) ;=> 1
(:a #{:a :b :c}) ;=> :a
('a {'a 1 'b 2 :c 3}) ;=> 1
Function-call forms
If the first element of a list form being evaluated is a function object, the expression will be treated as a function-call form, and the computed values of the remaining elements of the list will be passed as arguments to the subroutine associated with that object. This also applies to Java methods.
(print "Hello, Lisp!") ;=> nil =>> Hello, Lisp!
(+ 2 2) ;=> 4
(.toLowerCase "A") ;=> a
(print "Hello, Lisp!") ;=> nil =>> Hello, Lisp!
(+ 2 2) ;=> 4
(.toLowerCase "A") ;=> a
Special forms
If the first element of a list form being evaluated is one of the so-called syntax forms, the built-in handler subroutine for the associated special form will be launched, and the remaining elements of the list will become its arguments (after their prior evaluation or without evaluation).
(def x 1) ; defining a global variable
(fn [x] (inc x)) ; creating a function
(def f (fn [x] (inc x))) ; defining a named function
(let [a 1] a) ; creating lexical bindings
(quote (1 2 3)) ; quoting
(. System (getProperty "user.home")) ; accessing Java classes
(def x 1) ; defining a global variable
(fn [x] (inc x)) ; creating a function
(def f (fn [x] (inc x))) ; defining a named function
(let [a 1] a) ; creating lexical bindings
(quote (1 2 3)) ; quoting
(. System (getProperty "user.home")) ; accessing Java classes
Special forms are – as the name itself indicates – forms characterized by special evaluation rules. In essence, a special form is a kind of function built into the language, whose – similarly to macros – arguments are not all immediately evaluated.
Thanks to special forms we can, for example, define global variables or functions, and also create bindings of symbols to values in certain areas of a program.
Recursive evaluation of forms
When a datum obtained in the course of the evaluator’s work turns out not to be
a constant value, but another form requiring evaluation, it will be recursively
computed until a constant form is obtained. For example, a symbol form may emit
a Var reference object, which in turn will point to the subroutine of the
function being called.
Invalid forms
If it turns out that a given AST element is not a valid form – that is, one whose value cannot be computed (reduced to a constant form) – an error message will be generated and the program will terminate abnormally.
1(1 2 3) ; the number 1 cannot be cast to a function type
2(()) ; an empty list cannot be cast to a function type
3(+ /) ; the function / cannot be cast to an integer type
4(no_such) ; no construct identified by the symbol no_such
5no_such ; no construct identified by the symbol no_such
(1 2 3) ; the number 1 cannot be cast to a function type
(()) ; an empty list cannot be cast to a function type
(+ /) ; the function / cannot be cast to an integer type
(no_such) ; no construct identified by the symbol no_such
no_such ; no construct identified by the symbol no_such
The names of some forms are conventional – that is, they are based on the assumption that certain S-expressions can be computed to data of specific types. For example, the notation:
(add 1 2 3)
(add 1 2 3)
we will conventionally call a function-call form, even though in reality we are not
certain whether the symbol form add will be recognized in the namespace as a global
variable, and whether the reference object found there will contain a reference to
a function.
Binding forms
A binding form is a construct in which a value is assigned to a symbolic identifier in order to create a binding. At the syntactic level, these forms will contain unquoted symbols, but they will not be treated as symbol forms whose values need to be resolved; rather, they serve as expressions that assign in-memory objects to symbolic names.
We will recognize a binding form in expressions representing certain special forms, where we will encounter:
-
a pair composed of an unquoted symbol and another form (representing the value that, once computed, is to be assigned);
-
an unquoted symbol appearing on its own, e.g., in a function’s parameter vector, where the value will be dynamically assigned when arguments are passed during the function’s invocation.
Symbol binding forms are components of certain compound forms and special forms. We will find them, for example:
-
in the argument specifying a name:
-
in the bindings vector:
- of the special form
letand similar, - of the special form
loopand similar, - of the macro
with-local-vars, - of the macro
binding;
- of the special form
-
in the argument specifying a name and/or the parameter vector:
Additionally, binding forms may also appear in so-called structural bindings – that is, abstract bindings in which compound data structures are destructured and symbols are assigned values at specified positions or identified by given keys. We will then encounter a vector binding form or a map binding form, in which instead of a single unquoted symbol on the left side, a vector or map S-expression appears.
Some other constructs that use binding forms can also be intuitively referred to as
binding forms. These are expressions whose primary purpose is to create
bindings. For example, the special form let will also be called
a let binding form, even though in reality it uses potentially many basic binding
forms grouped in a bindings vector.
(def x 5) ; symbol x in a binding form
(fn [x] nil) ; symbol x in a binding form
(let [x 2]) ; symbol x in a binding form
(defn some-fn ; symbol some-fn in a binding form (function name)
[x] ; symbol x in a binding form (parameter name)
nil)
(def x 5) ; symbol x in a binding form
(fn [x] nil) ; symbol x in a binding form
(let [x 2]) ; symbol x in a binding form
(defn some-fn ; symbol some-fn in a binding form (function name)
[x] ; symbol x in a binding form (parameter name)
nil)
It is worth noting that in the case of function arguments, the symbols identifying their parameters will be dynamically assigned to the values of arguments passed at the moments of function invocation.
See also:
- “Bindings”;
- “Symbol binding forms”, chapter IV;
- “Bindings and namespaces”, chapter VI.
Quoting
An important special construct in Clojure and other Lisps is the special form quote,
which allows disabling evaluation of the S-expression given as its argument. A
syntactic construct written this way will be read and syntactically analyzed, but the
phase of semantic analysis will be skipped for it. Appropriate data structures will be
placed in the AST, but they will be marked as constant forms. Instead of computing
their values, the evaluator will simply return the data structures found in the syntax
tree.
In Lisp dialects, using the quote form allows creating literal variants of
structures that in their unquoted forms would be used to represent program source code
and/or would be evaluated.
quote form
1(quote one) ; literal symbol
2(quote (1 2 3)) ; literal list
3(quote [a b]) ; literal vector
4(quote {a 1 b 2}) ; literal map
5(quote #{1 2 3}) ; literal set
(quote one) ; literal symbol
(quote (1 2 3)) ; literal list
(quote [a b]) ; literal vector
(quote {a 1 b 2}) ; literal map
(quote #{1 2 3}) ; literal set
The above can also be written using syntactic sugar:
'one
'(1 2 3)
'[a b]
'{a 1 b 2}
'#{a b}
The same data structures could be produced without using quoting, by using the appropriate built-in functions of the language:
1(symbol "one") ; symbol
2(list 1 2 3) ; list
3(vector (symbol "a") (symbol "b")) ; vector
4(hash-map (symbol "a") 1 (symbol "b" 2}) ; map
5(hash-set 1 2 3) ; set
(symbol "one") ; symbol
(list 1 2 3) ; list
(vector (symbol "a") (symbol "b")) ; vector
(hash-map (symbol "a") 1 (symbol "b" 2}) ; map
(hash-set 1 2 3) ; set
Quoting is recursive – that is, every S-expression nested within a quoted one will also be quoted.
1(quote (a b c)) ; list with literal symbols
2(quote (+ 2 (* 2 3))) ; list with literal symbols and numbers
3(quote [one 2 3]) ; vector with a literal symbol and numbers
4(quote {a 1 b 2}) ; map with literal symbols and numbers
5(quote #{a b c}) ; set with literal symbols
(quote (a b c)) ; list with literal symbols
(quote (+ 2 (* 2 3))) ; list with literal symbols and numbers
(quote [one 2 3]) ; vector with a literal symbol and numbers
(quote {a 1 b 2}) ; map with literal symbols and numbers
(quote #{a b c}) ; set with literal symbols
It is worth noting that the terms “literal map”, “literal set”, and “literal vector” may in certain contexts be considered overly zealous labels. Each element of symbolically expressed maps, sets, or vectors will be eagerly evaluated by the evaluator, and their evaluation ends there. They remain the same data structures and do not carry the same syntactic weight as lists.
Augmenting the names of the above-mentioned structures with the qualifier “literal” will make sense when we want to emphasize that the contents of their elements will not be computed. An example would be a situation in which the elements of a vector S-expression are symbols pointing to certain values. When we quote such a construct, the values of elements will not be computed during vector evaluation. If we want to emphasize this fact, we can call the vector literal.
[1 2 3] ; vector form (colloq. vector, rarely: literal vector)
[1 2 (inc 2)] ; vector form (colloq. vector)
'[1 2 (inc 2)] ; literal vector (colloq. vector)
'[1 2] ; literal vector
[1 2 3] ; vector form (colloq. vector, rarely: literal vector)
[1 2 (inc 2)] ; vector form (colloq. vector)
'[1 2 (inc 2)] ; literal vector (colloq. vector)
'[1 2] ; literal vector
The most sensible approach seems to be to describe maps, vectors, and sets as literal when they are expressed in a quoted form. In the case of unquoted forms (subject to evaluation), colloquial terms can be used.
Let us also try quoting applied to our template program:
'(print "Hello, Lisp!")
'(print "Hello, Lisp!")
The result of evaluating the above expression is a value which is a list containing a symbol and a string – that is, our original program, expressible as the text:
(print "Hello, Lisp!")
It is worth noting that when a constant form is quoted, its value after evaluation is
still its own previous, constant value, as we can observe with the string
Hello, Lisp!.
Identifiers
Identifiers are constructs that allow us to name identities (e.g., individual values or compound data structures placed in memory) so that we can later refer to them.
In Clojure there are identification constructs (symbols, discussed below) that carry special syntactic meaning and whose named objects are resolved automatically. There are also constructs (e.g., keywords) that serve to identify utility data, but their use is not mandatory.
Symbols
A symbol in Clojure is a data type whose instances serve to identify structures placed in memory. Thanks to symbols (and the appropriate handling of them by the reader mechanisms) we can give names to functions and their arguments, to the results of computations, and to other objects, and subsequently refer to them using human-readable identifiers.
In Clojure, symbol forms can be expressed in program text without any additional markers. A symbol’s name is at the same time its own identifier, although the symbol object placed in the AST will be subject to further evaluation by the evaluator (it will not be self-evaluating).
Syntactically speaking, every symbol has a name that must be a string beginning
with a non-digit character and may contain alphanumeric characters as well as:
*, +, !, -, _, and ?.
1func ; func is a symbol form
2(func 1 2 3) ; func is a symbol form in a function-call form
3(fn [x y] x) ; symbols x and y are parameters of an anonymous function
4 ; [x y] contains two symbol binding forms
5(.toLowerCase "A") ; toLowerCase is a Java class method
6
7; ChunkedSeq is an inner class of PersistentVector
8(new clojure.lang.PersistentVector$ChunkedSeq [1 2 3 4 5] 0 3)
func ; func is a symbol form
(func 1 2 3) ; func is a symbol form in a function-call form
(fn [x y] x) ; symbols x and y are parameters of an anonymous function
; [x y] contains two symbol binding forms
(.toLowerCase "A") ; toLowerCase is a Java class method
; ChunkedSeq is an inner class of PersistentVector
(new clojure.lang.PersistentVector$ChunkedSeq [1 2 3 4 5] 0 3)
In many Lisps a symbol is a reference type, meaning it independently identifies another object by storing a reference to its in-memory structure. In Clojure things are different – a symbol does not hold any reference, and the fact that we can use symbol forms to invoke functions or refer to constant values is owed to the appropriate treatment by the evaluator and the searching of additional structures (e.g., namespaces or lexical bindings areas).
The dot character (.) within a symbol’s textual name carries special
significance, as it allows building identifiers that refer to class names
of the host system, i.e., Java.
Namespaced symbols
A symbol may optionally contain an additional name specifying a so-called namespace – a special collection that serves to group identifiers in order to eliminate conflicts. More details about using this visibility-control mechanism can be found later in this episode.
The namespace name is a string subject to the same syntactic rules as the symbol
name, and is expressed by placing it before the symbol name and separating it
with a slash (/), for example:
1my/func ; symbol func with namespace my
2(my/func 1 2) ; symbol func with namespace my in a function-call form
my/func ; symbol func with namespace my
(my/func 1 2) ; symbol func with namespace my in a function-call form
In the symbol object itself we will find no reference to the namespace other than a textual one. Here too, no reference is stored. We can specify a nonexistent namespace and it will not be an error – not until the evaluator begins evaluating the notation.
Literal symbols
We encounter symbols primarily in the abstract syntax tree, where they will be symbol forms representing identifiers of other objects. Additionally, we can use literal symbols (constant forms) in application logic. In that case they will serve, for example, as simple enumerated types, representing constant values belonging to fixed sets:
1(list (symbol "little") (symbol "much") (symbol "most"))
2(list 'little 'much 'most)
3'(little much most)
(list (symbol "little") (symbol "much") (symbol "most"))
(list 'little 'much 'most)
'(little much most)
The three notations above are equivalent. The first constructs a literal list
whose elements are symbols created from strings using the built-in symbol
function; the second also produces a list, but uses quoting to express literal
symbols; the third makes use of recursive quoting of the entire list
S-expression.
Constant forms of symbols may also include a namespace designation:
(symbol "name" "space")
'name/space
In Lisps, literal symbols are sometimes used as indexing keys in associative structures (e.g., maps):
{ 'little 21, 'much 108, 'most 11 }
{ 'little 21, 'much 108, 'most 11 }
In Clojure, using symbols for this purpose is not recommended because they are not interned – two symbols with the same name will be represented by two different in-memory objects. In other words: in Clojure, symbol instances with the same names are not singletons.
If we used symbols to index large, frequently accessed structures, a great many temporary objects would be created, and the garbage collector would have to deal with them at the cost of valuable time. Another drawback is less efficient comparison (and hence searching), since symbol names would be compared rather than internal object identifiers.
See also:
- “Symbols”, chapter IV.
Keywords
A keyword (colloquially called a key) is a data type that –
similarly to symbols – serves to identify other objects, but in Clojure it
carries no special syntactic meaning and keywords do not automatically identify
other program constructs. Keywords are represented by objects of type
clojure.lang.Keyword.
Unlike symbols, keywords are interned. Two keywords with the same name will be represented in memory by the same object (their singleton).
Keywords work well as simple enumerated types or as indices in associative data structures (e.g., maps). As for the built-in mechanisms of the Clojure language, we will encounter keywords in certain macros and in constructs that express named arguments bindings of functions.
From the syntactic point of view, every keyword has a name that must be a string
beginning with a colon (:) and may contain alphanumeric characters as well
as: *, +, !, -, _, and ?. In practice a slightly richer character
set may be used (e.g., the dot is increasingly common for denoting internal
hierarchies in some libraries), but this may change in the future, so it is
worth using key names consistent with the language documentation.
Keywords are also functions. When we place a keyword in the first position of a list S-expression, a subprogram will be invoked that tries to look up an index in an associative or set collection given as an argument.
Like symbols, keywords may optionally include a namespace designation.
:a-key ; keyword
::a-key ; keyword with current namespace
:space/a-key ; keyword with namespace
::user/a-key ; keyword with namespace (existing)
(keyword "a-key") ; keyword from a string
(keyword "space" "a-key") ; same but with namespace specified
{:a 1 :b 2} ; map with keyword indices
(defn x [& {:keys [color]}] color) ; function with a named keyword argument
(x :color 123) ; calling function with keyword argument
(:a {:a 1 :b 2}) ; keyword as a function searching a map
(:a #{:a :b :c :d}) ; keyword as a function searching a set
:a-key ; keyword
::a-key ; keyword with current namespace
:space/a-key ; keyword with namespace
::user/a-key ; keyword with namespace (existing)
(keyword "a-key") ; keyword from a string
(keyword "space" "a-key") ; same but with namespace specified
{:a 1 :b 2} ; map with keyword indices
(defn x [& {:keys [color]}] color) ; function with a named keyword argument
(x :color 123) ; calling function with keyword argument
(:a {:a 1 :b 2}) ; keyword as a function searching a map
(:a #{:a :b :c :d}) ; keyword as a function searching a set
See also:
- “Keywords”, chapter IV.
Namespaces
In Clojure a construct called a namespace is used. In information technology this term denotes a mechanism for controlling the visibility of identifiers that allows their hierarchical grouping in order to avoid conflicts. Common examples of namespaces include file system directory structures, DNS records, and public IP addresses.
Namespaces in computer programming help separate sets of identifiers used in different components (e.g., programming libraries) or contexts, so that the exposed names (e.g., of modules, classes, variables, or functions) are unique. We can then use several libraries in a program that define functions with the same name. When referring to such a function, a so-called fully qualified name will be required – an identifier enriched with a namespace designation.
In Clojure, namespaces are implemented as globally visible maps, i.e.,
dictionaries storing key-value mappings. In their case the keys are
symbols, and the values are global variables or Java classes. The
data type used to represent namespace objects is clojure.lang.Namespace.
Since symbols placed in a program may optionally include a namespace
designation, it is possible to use them to refer to identifiers from different
namespaces. If a symbol does not contain a fully qualified name, then during its
evaluation it is assumed that it identifies a construct defined in the current
namespace, pointed to by the dynamic global variable
clojure.core/*ns*:
;; symbol select from namespace clojure.set
;; identifies a function
(clojure.set/select odd? #{1 2 3 4})
;=> #{1 3}
;; symbol + from namespace clojure.core
;; imported into the current namespace (user)
;; identifies a function
(+ 2 2)
;=> 4
;; symbol select from namespace clojure.set
;; identifies a function
(clojure.set/select odd? #{1 2 3 4})
;=> #{1 3}
;; symbol + from namespace clojure.core
;; imported into the current namespace (user)
;; identifies a function
(+ 2 2)
;=> 4
The first symbol in the above example has the name select and its namespace
is specified by the string clojure.set. Since this is a function-call form,
it will be treated as the identifier of a function whose subprogram needs to
be executed. To find the function object, the namespace clojure.set will be
searched and within it the key identified by the symbol select and the
global variable assigned to it. Inside the reference object,
a reference to the function subprogram will be found and invoked with the
arguments given as the subsequent elements of the list S-expression (odd? and
#{1 2 3 4}).
The second symbol in the example has no namespace specified. The evaluator will
therefore read the contents of the dynamic global variable *ns*, which by
default in the REPL console points to the namespace user. There it will find
the binding of the symbol + to a Var object, which refers to the
built-in addition function. The latter does not originally reside in the
namespace user but was imported into it along with other mappings from the
namespace clojure.core when the console was started.
See also:
- “Bindings and namespaces”, chapter VI.
Handling global state
When talking about Clojure, it is emphasized that there are no conventional variables and that data structures are immutable. Why, then, does the term “global variable” keep appearing?
Every programming language must handle changing global state – values that undergo change and are visible throughout the entire program under fixed names. Examples include: a character’s condition in a game, the arrangement of windows in a user interface, or the currently processed contents of a file being read.
To represent such data one might use conventional variables – fixed memory locations with given names whose contents are modified by appropriate subprograms (e.g., updating a score, reacting to user actions on interface elements, or reading data from a database). However, in such a model we cannot use multiple threads without applying additional isolation mechanisms. The memory slot of a variable representing an important parameter may be reorganized by one thread while another is still performing a critical operation with it. This means more work for the programmer, who instead of focusing on the application’s business logic must remember to safeguard the program against itself by introducing semaphores, locks, and similar constructs.
The opposite approach is to give up shared state entirely – a purely functional model in which no already-used memory area can ever be modified and the entire program consists of operations whose only input is their arguments and whose only output is their returned values. Handling graphical interfaces or tracking the activity of a logged-in user would in such a setup be cumbersome to express and inefficient. Imagine every user action triggering a cascade of function calls that each time recompute from scratch the values of all parameters constituting the program’s state at a given moment.
In Clojure we encounter a sensible compromise. Conventional variables do not exist, but thanks to appropriate reference types we are able to track and manage changing global state. This means that data mutations are permissible, but only as an exception and only using special constructs.
Reference objects in Clojure are equipped with concurrency-safe mechanisms for updating and reading the current values they point to. Instead of directly modifying the memory area containing data, an update to the reference takes place in such a way that the object begins pointing to a new value (placed at a different location). Values therefore remain constant and need not reside in variables, because the only element that undergoes mutation (overwriting of memory space) is the reference to them residing in reference objects.
The Var type
The most widely used reference type in Clojure is Var. It allows
creating references to data placed in memory and changing those references
within a given thread of execution. Additionally, a Var object may
optionally contain a so-called root binding, which is shared across all threads
and used when no thread-specific binding has been set.
By convention, Var objects in Clojure are interned in namespaces – there
is no commonly used special form or function that would allow creating them
without binding them to some symbolic identifier. There is, however, the
with-local-vars macro, which creates Var objects in lexical scope – they
must then be identified by given symbols visible within the expression passed
as an argument. We can read the values they point to using the deref function
or the dereference literal (the at sign placed before the symbol):
(with-local-vars [a 5] @a)
;=> 5
(with-local-vars [a 5] @a)
;=> 5
See also:
- “The Var type”, chapter VII.
Global variables
Objects of type Var (more precisely clojure.lang.Var) are used together with
symbols in Clojure to create global variables. Global variables serve to
identify infrequently changing identities, e.g., configuration values or
functions defined in the program.
It works as follows: a particular Var is assigned to a symbolic name by
placing an entry in one of the namespaces. This creates a global
binding of a symbol to the current value of the Var
object.
Let us look at a diagram illustrating how a function object is obtained from its name in our example program:
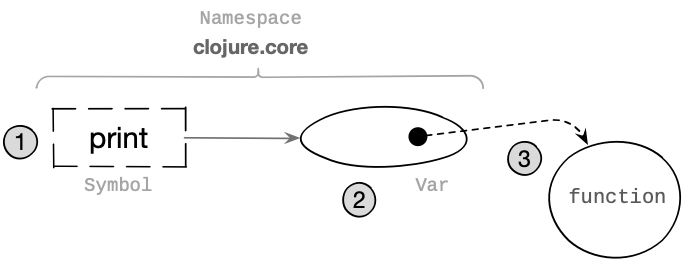
The evaluator performed 3 essential steps to obtain the invoked function’s subprogram:
-
It searched the namespace
clojure.coreto find the value assigned to the symbolprint. -
It obtained a
Varobject and passed it to the appropriate subprogram to read the current value of the reference. -
It found the function object pointed to by the reference variable, whose subprogram can be invoked.
Creating global variables is possible using the def special form:
1(def x 8) ; x points to the value 8
2(def y [1 2 3]) ; y points to the vector [1 2 3]
3(def write print) ; write points to the current value of print variable
4(declare later) ; creates a global variable without binding to a value
5
6(write x) ;=> 8
7(write y) ;=> [1 2 3]
8(write "Hello, Lisp!") ;=> Hello, Lisp!
9
10later
11;=> #object[clojure.lang.Var$Unbound 0x53245a5b "Unbound: #'user/later"]
(def x 8) ; x points to the value 8
(def y [1 2 3]) ; y points to the vector [1 2 3]
(def write print) ; write points to the current value of print variable
(declare later) ; creates a global variable without binding to a value
(write x) ;=> 8
(write y) ;=> [1 2 3]
(write "Hello, Lisp!") ;=> Hello, Lisp!
later
;=> #object[clojure.lang.Var$Unbound 0x53245a5b "Unbound: #'user/later"]
See also:
- “Bindings and namespaces”, chapter VI;
- “Global variables”, chapter VI.
Bindings
A binding is, in general terms, an association of an identifier with an identified object. Using this term helps us avoid misunderstandings related to the subtle but – from the programmer’s perspective – important differences in how objects are referred to by names.
In imperatively rooted languages we often use the concept of a “variable” and expect, by force of habit, that it will have some name. The term lets us point to a memory slot in which we will find a value. In Clojure this approach could be misleading, because we can create nameless variables (reference objects) as well as name values that are not variables at all.
In Clojure we encounter several kinds of bindings:
-
Global variables are bindings of:
- symbols to
Varobjects in namespaces, - symbols to Java classes in namespaces.
- symbols to
-
Lexical bindings are bindings of symbols to values within the binding vector of the
letspecial form. -
Parameter vectors are symbol binding forms with accepted arguments in function and macro definitions.
-
Structural bindings are abstract bindings of:
- symbols to values at indicated positions of sequential collections,
- symbols to values identified by keys of associative collections.
-
Reference type objects are bindings of objects to the current values they point to.
The last item requires explanation, because – as is easy to notice – it contains no mention of any symbol, and we have repeatedly stated that it is symbols that serve to identify other objects.
At this point it is worth recalling that in Clojure symbols do not
independently store references to values – this function is performed by
reference objects (e.g., of type Var in the case of global
variables). This follows from the adopted model of managing mutable state.
;; global variable
;; initial value pointed to by x is 1
(def x 1)
;=> #'user/x
;; parameter vector of a function definition
;; the first two arguments become parameters a and b
(fn [a b] (+ a b))
;=> #<Fn@5af25442 user/eval14406[fn]>
;; lexical binding
;; symbol a identifies the value 1
(let [a 1]
a)
;=> 1
;; positional decomposition in let
;; symbol a bound to value 1 by position
;; symbol b bound to value 2 by position
(let [[a b] '(1 2 8)]
(+ a b))
;=> 3
;; associative decomposition in let
;; symbol a bound to value 1 by key :a
;; symbol b bound to value 2 by key :b
(let [{a :a b :b} {:a 1 :b 2 :c 8}]
(+ a b))
;=> 3
;; associative decomposition in let (using :keys)
;; symbol a bound to value 1 by key :a
;; symbol b bound to value 2 by key :b
(let [{:keys [:a :b]} {:a 1 :b 2 :c 8}]
(+ a b))
;=> 3
;; binding a Var reference object to a value
(with-local-vars [x 5] x)
;=> #'Var: --unnamed-->
;; binding an Atom reference object to a value
(atom 5)
;=> #<Atom@a1cb453 5>
;; global variable
;; initial value pointed to by x is 1
(def x 1)
;=> #'user/x
;; parameter vector of a function definition
;; the first two arguments become parameters a and b
(fn [a b] (+ a b))
;=> #<Fn@5af25442 user/eval14406[fn]>
;; lexical binding
;; symbol a identifies the value 1
(let [a 1]
a)
;=> 1
;; positional decomposition in let
;; symbol a bound to value 1 by position
;; symbol b bound to value 2 by position
(let [[a b] '(1 2 8)]
(+ a b))
;=> 3
;; associative decomposition in let
;; symbol a bound to value 1 by key :a
;; symbol b bound to value 2 by key :b
(let [{a :a b :b} {:a 1 :b 2 :c 8}]
(+ a b))
;=> 3
;; associative decomposition in let (using :keys)
;; symbol a bound to value 1 by key :a
;; symbol b bound to value 2 by key :b
(let [{:keys [:a :b]} {:a 1 :b 2 :c 8}]
(+ a b))
;=> 3
;; binding a Var reference object to a value
(with-local-vars [x 5] x)
;=> #'Var: --unnamed-->
;; binding an Atom reference object to a value
(atom 5)
;=> #<Atom@a1cb453 5>
See also:
- “Bindings and namespaces”, chapter VI.
Collections
A collection is a data structure that allows storing a certain number of elements.
Lists
In Lisp the most commonly used data structure is the list, which – as we have had the chance to observe – serves both for the syntactic organization of program code (list S-expressions) and for storing ordered collections of elements for the purposes of application logic. It is worth thinking of a list as a way of arranging data, not merely a symbolic notation with parentheses.
There are several kinds of lists. The most commonly used in Lisp dialects are so-called linked lists, and more specifically singly linked lists. They are characterized by the ability to flexibly link elements together and to quickly add new ones to their beginnings. This is why they serve their role well as in-memory representations of Lisp program structures.
Lists in early Lisps
Historically speaking, each node of a list (in Lisp called a cons cell) has two slots: the first points to the value of the current element, and the second to the next element of the list (the next cons cell). In reality these are simply two pointers that can refer to arbitrary values.
Access to the first slot of each element is called car (from Contents of
the Address part of Register number), and to the second cdr (from Contents
of the Decrement part of Register number). The etymology of these peculiar
names goes back to the time when Lisp was implemented on the IBM 704 computer
(the 1950s). That machine had a special instruction that divided a 36-bit
machine word into 4 parts – car and cdr are the abbreviated labels of the
first two, and they found their way into Lisp because the author used them to
divide the contents of the internal structure representing a list cell. In
jargon, the first slot of a cons cell is therefore referred to as CAR, and the
second as CDR.
There is nothing preventing a list from containing another list within it:
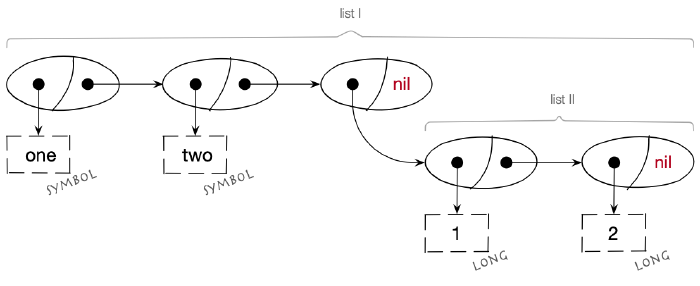
In code we can express the above structure as:
(one two (1 2))
(one two (1 2))
that is:
1(one ; first element of the list
2 two ; second element of the list
3 ( ; third element of the list -- a nested list
4 1 ; first element of the nested list
5 2)) ; second element of the nested list
(one ; first element of the list
two ; second element of the list
( ; third element of the list -- a nested list
1 ; first element of the nested list
2)) ; second element of the nested list
And here is the notation using so-called full notation, which is not used in Clojure. Inside each pair of parentheses we find two slots separated by a dot:
(one . (two . ((1 . (2 . nil)) . nil)))
(one . (two . ((1 . (2 . nil)) . nil)))
The dots separate the CAR and CDR registers of the cells, and the nil
elements denote the ends of lists. If the second slot (CDR) is to point to the
next element of the list, in this notation that next element is placed after the
dot and enclosed in parentheses.
Let us remember, however, that the notation (one two (1 2)) is a valid
S-expression but not a form – unless we define a function named one and
associate the symbol two with some value. We can also use quoting to strip
the construct of its special meaning so that it expresses a constant form:
'(one two (1 2))
'(one two (1 2))
In the earliest editions of Lisp, lists were constructed using the cons
function (from construct). For example:
(cons 'one (cons 'two (cons (cons 1 (cons 2 nil)) nil)))
(cons 'one (cons 'two (cons (cons 1 (cons 2 nil)) nil)))
Which can also be presented as:
(cons 'one
(cons 'two
(cons (cons 1
(cons 2 nil))
nil)))
Such list construction may exercise the mind, but it does not serve productive
programming. At present some Lisp dialects have dropped support for full
notation, although the cons function is still used – mainly for
performing operations on existing lists rather than constructing them from
scratch.
Lists in Clojure
In Clojure, lists are represented by the host system’s object data type called
clojure.lang.PersistentList. Objects of this type can be found in the syntax
tree, where they reflect list S-expressions, as well as in application data
when the list function is used or a literal list is produced by
quoting its symbolically expressed form.
1(list 1 2 3) ; using the list function (arguments will be evaluated)
2(quote (1 2 3)) ; literal list (arguments will not be evaluated)
3'(1 2 3) ; literal list (arguments will not be evaluated)
(list 1 2 3) ; using the list function (arguments will be evaluated)
(quote (1 2 3)) ; literal list (arguments will not be evaluated)
'(1 2 3) ; literal list (arguments will not be evaluated)
Internally, PersistentList objects are doubly linked lists, although this
property is hidden from the programmer. Moreover, in Clojure a list (like most
data structures) is immutable – to introduce a change in its structure one
never modifies the object representing it but instead creates a new one that
differs from the previous one.
See also:
“Lists”, chapter IX.
Sequences and Cons objects
Apart from encapsulated lists, Clojure also provides objects of type Cons
(more precisely clojure.lang.Cons). They are the closest counterpart of
cons cells known from other Lisp dialects. More precisely, using cons we can
construct so-called sequences – abstract collections characterized by
a uniform access interface consisting of three basic operations:
- reading the value stored in the cell,
- reading the next cell linked to the current one,
- attaching a new cell to an existing one.
We can place references to values of arbitrary types in Cons objects and link
them into sequences using the cons function. It accepts two
arguments: a value and an object also equipped with a sequential interface
(these include, among others, lists, vectors, and maps). The returned
value will be a Cons cell whose next cell is the one provided as an argument.
If the provided existing object is nil, a single-element list will be
returned.
1(def the-first (cons 3 nil)) ; creates the list (3)
2(def the-second (cons 2 the-first)) ; creates cons(2)-->(3)
3(def the-last (cons 1 the-second)) ; creates cons(1)-->cons(2)-->(3)
4
5(first the-last) ; => 1 ; value in the last added cell
6(first (rest the-last)) ; => 2 ; value in the next cell
(def the-first (cons 3 nil)) ; creates the list (3)
(def the-second (cons 2 the-first)) ; creates cons(2)-->(3)
(def the-last (cons 1 the-second)) ; creates cons(1)-->cons(2)-->(3)
(first the-last) ; => 1 ; value in the last added cell
(first (rest the-last)) ; => 2 ; value in the next cell
Using Cons we can join not only individual values but also collections
(e.g., ordinary lists). We then have a compound structure that can be
expressed, for example, like this:
(cons (list 1 2 3)
(cons (list 4 5 6)
(cons 10
())))
; => ((1 2 3) (4 5 6) 10)
Such structures are sometimes used to quickly join already grouped values into larger sets that are flattened only when being read in order to obtain individual values.
(flatten
(cons '(1 2 3) (cons '(4 5 6) (cons 10 nil))))
; => (1 2 3 4 5 6 10)
See also:
“Cons cells”, chapter X.
Vectors
A vector is an ordered collection of values indexed using integers starting from 0 (the first element). In program code we use the vector literal to express vectors; we can also use several built-in functions.
Vectors in Clojure are represented by objects of type
clojure.lang.PersistentVector. They are characterized by very fast data
lookup and adding new elements to their ends. Vectors are also functions –
they accept one argument, an index number, whose element value will be
returned.
;; creating a vector (function)
(vector 1 2 3 4)
;=> [1 2 3 4]
;; creating a vector from an S-expression (literal)
[1 2 3 4]
;=> [1 2 3 4]
;; creating a vector from another collection
(vec (list 1 2 3 4))
;=> [1 2 3 4]
;; searching a vector (element at index 0)
([1 2 3 4] 0)
;=> 1
;; creating a vector (function)
(vector 1 2 3 4)
;=> [1 2 3 4]
;; creating a vector from an S-expression (literal)
[1 2 3 4]
;=> [1 2 3 4]
;; creating a vector from another collection
(vec (list 1 2 3 4))
;=> [1 2 3 4]
;; searching a vector (element at index 0)
([1 2 3 4] 0)
;=> 1
See also:
- “Vectors”, chapter IX.
Maps
A map is an associative collection that stores mappings of keys to values. Keys and values may be data of any type, but the same key must be unique within a given map. Searching maps for a value identified by a key is very fast, as is adding new elements.
In Clojure, maps are represented by the following data types:
clojure.lang.PersistentHashMap(a map based on hash tables),clojure.lang.PersistentArrayMap(a map based on plain arrays),clojure.lang.PersistentTreeMap(a sorted map).
In program code we express maps using the map literal in the form of curly
braces containing pairs of expressions. We can also use the hash-map function
to express pairs as successive invocation arguments.
;; creating a map (function)
(hash-map :a 1 :b 2)
;=> {:a 1 :b 2}
;; creating a sorted map (function)
(sorted-map :a 1 :b 2)
;=> {:a 1 :b 2}
;; creating a map from an S-expression (literal)
{:a 1 :b 2}
;=> {:a 1 :b 2}
;; creating a map from an S-expression (literal)
{:a 1 :b (+ 1 1)}
;=> {:a 1 :b 2}
;; creating a map from two sequential collections
(zipmap [:a :b] [1 :b 2])
;=> {:a 1 :b 2}
;; creating a map from a sequence of pairs
(into {} [[:a 1] [:b 2]])
;=> {:a 1 :b 2}
;; creating a map from a sequence
(apply hash-map [:a 1 :b 2])
;=> {:a 1 :b 2}
;; creating a map (function)
(hash-map :a 1 :b 2)
;=> {:a 1 :b 2}
;; creating a sorted map (function)
(sorted-map :a 1 :b 2)
;=> {:a 1 :b 2}
;; creating a map from an S-expression (literal)
{:a 1 :b 2}
;=> {:a 1 :b 2}
;; creating a map from an S-expression (literal)
{:a 1 :b (+ 1 1)}
;=> {:a 1 :b 2}
;; creating a map from two sequential collections
(zipmap [:a :b] [1 :b 2])
;=> {:a 1 :b 2}
;; creating a map from a sequence of pairs
(into {} [[:a 1] [:b 2]])
;=> {:a 1 :b 2}
;; creating a map from a sequence
(apply hash-map [:a 1 :b 2])
;=> {:a 1 :b 2}
See also:
- “Maps”, chapter IX.
Sets
A set is a data structure that allows storing elements of arbitrary values with the restriction that a given value may appear in the set only once. Sets are characterized by very fast addition and lookup of elements. In Clojure there are built-in functions intended for performing operations on sets, e.g., join, projection, union, etc.
Sets are represented by objects of the following data types:
clojure.lang.PersistentSet(a set based on hash tables),clojure.lang.PersistentTreeSet(a sorted set).
;; creating a set (function)
(hash-set :a :b :c)
;=> #{:a :b :c}
;; creating a sorted set (function)
(sorted-set :a :b :c)
;=> #{:a :b :c}
;; creating a set from an S-expression (literal)
#{:a :b :c}
;=> #{:a :b :c}
;; creating a set from an S-expression (literal)
#{:a :b (keyword "c")}
;=> #{:a :b :c}
;; creating a set from a sequence
(set [:a :b :c])
;=> #{:a :b :c}
;; creating a set (function)
(hash-set :a :b :c)
;=> #{:a :b :c}
;; creating a sorted set (function)
(sorted-set :a :b :c)
;=> #{:a :b :c}
;; creating a set from an S-expression (literal)
#{:a :b :c}
;=> #{:a :b :c}
;; creating a set from an S-expression (literal)
#{:a :b (keyword "c")}
;=> #{:a :b :c}
;; creating a set from a sequence
(set [:a :b :c])
;=> #{:a :b :c}
See also:
- “Sets”, chapter IX.
Functions
A function is a construct containing code that, during invocation, computes a value for a given set of arguments. In purely functional languages this is the only result of using a function, while in others (including Clojure) functions may produce so-called side effects – that is, besides returning a value, they may affect their surroundings (e.g., modifying the value of a global variable or using the I/O subsystem).
Moreover, the result of a function’s operations in Clojure may depend on its surroundings. An example would be referencing global reference objects expressing some mutable state within its computations, or using values originating from the lexical environment of the function’s definition. In the latter case we call such a function a closure.
A function definition in Clojure consists of a list S-expression containing:
- a vector S-expression defining the argument list,
- one or more S-expressions constituting the function body.
In Clojure we can also use multi-arity functions, which can handle more than one set of arguments. In their case the definition syntax will be somewhat different.
The return value of a function is the computed value of the last S-expression from its body (or from the body of a given arity in the case of a multi-arity function).
In Clojure, to create anonymous functions we use the fn special
form, and to create named functions we use the defn macro.
Anonymous functions are function objects that have not been given names. Named
functions in Clojure have names expressed through global variables.
1(defn shout ; named function definition
2 [text] ; vector with arguments
3 (print text "!")) ; calling print with parameter text
4
5(shout "Hello, Lisp") ; function call with argument
6;=>> Hello, Lisp! ; result of call on screen
7;=> nil ; returned value
(defn shout ; named function definition
[text] ; vector with arguments
(print text "!")) ; calling print with parameter text
(shout "Hello, Lisp") ; function call with argument
;=>> Hello, Lisp! ; result of call on screen
;=> nil ; returned value
We can also create an anonymous version of the above function, but for the purposes of the example we must place the entire construct in an S-expression representing a function-call form so that we can observe the result of its execution:
1( ; function-call form
2 (fn ; anonymous function definition
3 [text] ; vector with arguments
4 (print text "!")) ; calling print with parameter text
5 "Hello, Lisp!") ; function call argument
6
7;=>> Hello, Lisp! ; result of call on screen
8;=> nil ; returned value
( ; function-call form
(fn ; anonymous function definition
[text] ; vector with arguments
(print text "!")) ; calling print with parameter text
"Hello, Lisp!") ; function call argument
;=>> Hello, Lisp! ; result of call on screen
;=> nil ; returned value
The above can also be expressed using the anonymous function literal:
1( ; function-call form
2 #(print %1 "!") ; definition and calling print with first parameter
3 "Hello, Lisp!") ; function call argument
4
5;=>> Hello, Lisp! ; result of call on screen
6;=> nil ; returned value
( ; function-call form
#(print %1 "!") ; definition and calling print with first parameter
"Hello, Lisp!") ; function call argument
;=>> Hello, Lisp! ; result of call on screen
;=> nil ; returned value
Nothing prevents us from defining an anonymous function and then assigning it a name ourselves:
1(def shout ; global variable definition
2 (fn ; anonymous function definition
3 [text] ; vector with arguments
4 (print text "!"))) ; calling print with parameter text
5
6(shout "Hello, Lisp") ; function call with argument
7;=>> Hello, Lisp! ; result of call on screen
8;=> nil ; returned value
(def shout ; global variable definition
(fn ; anonymous function definition
[text] ; vector with arguments
(print text "!"))) ; calling print with parameter text
(shout "Hello, Lisp") ; function call with argument
;=>> Hello, Lisp! ; result of call on screen
;=> nil ; returned value
In the above example we define a global variable shout with an initial value
assigned to the result of invoking the fn special form, which will be
a function object – a representation of an existing function.
In Lisp, functions are first-class citizens – values that can be treated like any other: passed as arguments or returned as results of function execution.
See also:
- “Functions and closures”, chapter VIII.
Boolean values
To express boolean values in Clojure we can use the singletons of type
java.lang.Boolean: true denoting logical truth and false
denoting logical falsehood. These values are returned by built-in predicates
(functions that return logical truth or falsehood based on their arguments) and
conditional constructs.
Indeterminate value
The literal for the indeterminate value nil, whose name comes from the
English expression not in list, has special meaning in Clojure and serves to
express an object representing an indeterminate value or the absence of
a value. Internally, nil is represented by the Java value null (a null
pointer).
The nil construct is used in Clojure to communicate that a given form does
not return any value, or that a value could not be obtained. Many built-in
functions and conditional constructs use it. In the case of functions, nil
denotes the absence of a result (returned value) or a default initial value
(accepted argument), while in the case of conditionals it corresponds to the
logical value of falsehood (false). Furthermore, in sequence
handling the value nil is used to mark their ends.
Comments
Comments in computer programs serve to explain fragments of source code in natural language. They may serve a documentary purpose or contain notes regarding progress on certain tasks. Sometimes they are also used to present the results of computing example forms.
In Clojure a comment begins with the semicolon character (;), after which
we place arbitrary text. The comment will consist of any sequence of characters
up to the end of the line in which it was started:
1(print "Hello, Lisp!") ; this is a comment
2
3;; This is a longer comment
4;; written according to the convention
5;; of preceding each line
6;; with two semicolons.
7
8;; The comments below
9;; are used to present computation results.
10
11(+ 2 2) ; => 4
12(- 2 2) ; => 0
13
14(+ 2 2)
15; => 4
16
17'(1 2 3)
18; => (1 2 3)
(print "Hello, Lisp!") ; this is a comment
;; This is a longer comment
;; written according to the convention
;; of preceding each line
;; with two semicolons.
;; The comments below
;; are used to present computation results.
(+ 2 2) ; => 4
(- 2 2) ; => 0
(+ 2 2)
; => 4
'(1 2 3)
; => (1 2 3)
Comment form
Apart from syntactic comments expressed with the semicolon, Clojure provides a special macro that allows disabling the computation of a given S-expression:
(comment
(print "Hello, Lisp!")
123)
(comment
(print "Hello, Lisp!")
123)
It is worth noting that comment is a construct to which syntactically valid
symbolic expressions must be passed as arguments.
The value returned by the macro is nil.
Ignoring the next form
Another way of excluding part of a program from the value-computation process
is to use the reader macro #_. It causes the next form placed after it to not
be evaluated:
#_ (print "Hello, Lisp!") ; disables the function-call form
(#_#_ print "Hello, Lisp!") ; disables the first two nested forms
(print #_ "Hello, Lisp!") ; disables the constant form "Hello, Lisp!"
[#_#_ 1 2 3] ; disables two nested constant forms 1 and 2
#_ (print "Hello, Lisp!") ; disables the function-call form
(#_#_ print "Hello, Lisp!") ; disables the first two nested forms
(print #_ "Hello, Lisp!") ; disables the constant form "Hello, Lisp!"
[#_#_ 1 2 3] ; disables two nested constant forms 1 and 2
Control structures
Clojure is equipped with many special forms and macros that serve to control the expression-evaluation process, including the order of evaluation, the number of repetitions, and conditional processing.
Conditional expressions
The conditional statements known from imperative languages have counterparts in Lisps as conditional special forms or macros. A special form and a macro differ from a function in that certain arguments passed to them may or may not be evaluated (depending on the specific form) before the subprogram is invoked. Thanks to this property it is possible to build, among other things, expressions in which the evaluation of certain arguments depends on the result of evaluating other (earlier) ones. We can thus control whether and when the pass-by-value principle takes effect, and thereby build conditional constructs or loops.
Special forms and macros will be discussed later, and the fundamental difference between them is that macros are a language feature allowing source code transformations, whereas special forms are constructs built into the evaluator. Both may have evaluation and argument-passing behavior that differs from the default, and may affect the surroundings (the state of other in-memory objects).
Conditional execution, if
The if special form serves for conditional evaluation of expressions.
Usage:
(if predicate true-expression false-expression?).
The if form accepts two mandatory arguments. The first is a condition to be
evaluated; if its value is neither false nor nil, the next
argument will also be evaluated. If an optional third argument is provided, it
will be evaluated only when the first argument has the value false or nil.
The if special form returns the value of the most recently evaluated
expression, or nil if no third argument was provided and the first expression
returned a logical falsehood.
if special form
(if (= 2 2)
"equal"
"different")
; => "equal"
Together with the if form, the and macro is frequently used. It
serves to express the logical conjunction (logical AND) operation. It
evaluates the values of expressions given as its arguments (in the order they
appear) as long as their value is logical truth (not false and
not nil). The returned value is then the value of the last given
expression. If any expression returns false or nil, processing of
subsequent arguments is halted and its value is returned.
and macro
(if (and (= 2 2) (< 2 3)) true)
; => true
Another macro found alongside if is or. It serves to express the
logical disjunction (logical OR) operation. This macro evaluates the
values of successive expressions given as its arguments (in the order they
appear) until the value of one of them is logical truth (not
false and not nil). The returned value is then the value of
the most recently processed expression. If the values of all expressions are
false or nil, the value of the last given expression is
returned (false or nil).
or macro
(if (or (= 2 2) (< 4 3)) true)
; => true
Conditional execution, if-not
The if-not macro is the inverse version of the if special form.
Usage:
(if-not predicate false-expression true-expression?).
The macro accepts two mandatory arguments. The first is a condition to be
evaluated; if its value is logical falsehood (false or nil), the next
argument will also be evaluated. If an optional third argument is provided, it
will be evaluated only when the first argument represents logical truth
(has a value different from false and different from nil).
The if-not macro returns the value of the most recently evaluated expression,
or nil if no third argument was provided and the first expression returned
logical truth.
if-not macro
(if-not (= 2 2)
"different"
"equal")
; => "equal"
Conditional execution, when
The when macro works similarly to the if construct, but is somewhat
simpler because there is no place for an alternative expression (one executed
when the given condition is not met).
Usage:
(when predicate & expression...).
The first argument should be a form expressing a logical condition (one
returning true or false, or possibly nil), and each
remaining argument will be treated as an expression that will be evaluated when
the value returned by the conditional construct is logical truth (a value
different from false and different from nil).
when macro
1(when (= 2 2)
2 (println "you can provide")
3 (println "multiple expressions"))
4
5; >> you can provide
6; >> multiple expressions
(when (= 2 2)
(println "you can provide")
(println "multiple expressions"))
; >> you can provide
; >> multiple expressions
Conditional execution, when-not
The when-not macro is the inverse version of the when macro.
Usage:
(when-not predicate & expression...).
The first argument should be a predicate, and each remaining argument will be
treated as an expression that will be evaluated when the predicate’s value is
logical falsehood (false or nil).
when-not macro
1(when-not (= 2 1)
2 (println "you can provide")
3 (println "multiple expressions"))
4
5; >> you can provide
6; >> multiple expressions
(when-not (= 2 1)
(println "you can provide")
(println "multiple expressions"))
; >> you can provide
; >> multiple expressions
Condition list, cond
The cond macro allows writing a list of conditions with corresponding
expressions that will be evaluated when a given condition is met.
Usage:
(cond & pair...),
where pair is:
predicate expression,:else default-expression.
The macro accepts an even number of arguments. For each pair it checks whether
the given conditional expression returns a value different from false and from
nil. If so, the associated argument from the pair (the expression) will be
evaluated, processing of further arguments will stop, and the returned value
will be the value of the evaluated expression.
Optionally, a final pair (option) can be added whose first element equals
:else. Its associated expression will be evaluated when none of the earlier
options terminated the process. This allows setting a default return value.
If no default option was given and no condition was met, the returned value
will be nil.
cond macro
1(cond
2 (= 2 3) "2 and 3 are equal"
3 (< 2 3) "2 is less than 3"
4 :else "neither")
5
6; => "2 is less than 3"
(cond
(= 2 3) "2 and 3 are equal"
(< 2 3) "2 is less than 3"
:else "neither")
; => "2 is less than 3"
Case list, case
The case special form works similarly to cond, but instead of
conditional expressions in the options, constant values should be given that
will be matched against the value of the first argument provided.
Usage:
(case value option...),
where option is:
value expression,(value...) expression,default-expression.
If we want to compare the given value against multiple values from a series for each possible option, that series of possibilities should be written as a list S-expression.
The values against which the first argument’s value will be compared must be constant forms, since they are processed at compile time. We may therefore provide literals or other atomic representations that express their own values. The expressions to be evaluated upon a positive test may, in turn, represent arbitrary forms.
Optionally, a last argument can be provided as an expression that will be evaluated if the tested value does not satisfy any of the earlier conditions. It is worth using this possibility, because otherwise the program will throw an exception when no match is found.
case special form
1(def x 'cookies) ; x refers to the symbol cookies
2
3(case x
4 "" "nothing"
5 (mints dragees) "sweets"
6 (cookies gingersnaps) "biscuits"
7 (str x " is an unknown product"))
8
9; => "biscuits"
(def x 'cookies) ; x refers to the symbol cookies
(case x
"" "nothing"
(mints dragees) "sweets"
(cookies gingersnaps) "biscuits"
(str x " is an unknown product"))
; => "biscuits"
It is worth noting that the symbols and lists were not quoted. This is precisely a property of special forms – certain expressions are not evaluated, so there is no need to employ special techniques to prevent evaluation.
Condition list with predicate, condp
The condp macro works similarly to cond, but is much more flexible.
Usage:
(condp predicate expression & pair...)
The first argument should be a predicate – a function that should return a boolean value – and the second an expression. The subsequent, optional arguments are options composed of pairs, which can be expressed using the following notations:
test-expression result-expression,test-expression :>> result-function,default-expression.
The symbolic notation :>> is a keyword that carries special
meaning in the context of the condp macro.
For each given option, the associated function-call form will be evaluated:
(predicate test-expression expression).
The predicate will be invoked for each option given in order with two passed arguments. The first will be the value of the test expression of the given option, and the second will be the expression given as the argument to the entire macro invocation.
If the predicate returns a value corresponding to logical truth (different from
false and different from nil), checking of subsequent options will stop and
the result expression associated with the current option will be returned,
or the value produced by invoking the result function (in the case where
the :>> keyword was used). In this latter case, the value returned by the
predicate will be passed to the function (which should accept one argument).
If a final additional expression was given as the last option
(default-expression), its value will be returned if none of the options
matched the given data. When such a situation occurs but no default expression
was provided, the returned value will be nil.
condp macro
1(condp
2 = ; predicate
3 (+ 2 2) ; expression (yields 4)
4 1 "one" ; option 1: string
5 2 "two" ; option 2: string
6 3 "three" ; option 3: string
7 4 "four" ; option 4: string
8 "none") ; default option expression
9
10; => "four"
(condp
= ; predicate
(+ 2 2) ; expression (yields 4)
1 "one" ; option 1: string
2 "two" ; option 2: string
3 "three" ; option 3: string
4 "four" ; option 4: string
"none") ; default option expression
; => "four"
Java member access
Member access, .
The . special form in Clojure provides access to Java objects. It is de
facto a member-access operator.
-
When the first argument is a symbol naming a Java class, the evaluator will treat the notation as access to a static member of that class.
-
If the first argument is not a Java class name, the evaluator will assume it is a class instance on which we want to invoke a method or access a field value. If no further arguments are provided, it will be a field – unless a public method with the given name that takes no arguments exists, in which case it will be invoked. If both a field with the given name and a method exist, prefixing the symbolic name with a hyphen (
-) will indicate that the field is intended. -
If additional arguments are given beyond the first, a method of the instance with the name given as the first argument will be invoked. The additional arguments will (from left to right) be passed to the invocation after their values are evaluated.
Additional arguments may also be a list S-expression. In such a case, the first element should be a symbol identifying the method to invoke.
There is also a simplified version of this special form in which the dot is part of the symbolic name of the object’s member, which is given as the next argument.
. special form
(. " a " trim) ; => a
(.trim " a ") ; => a
(. "abc" substring 0 1) ; => a
(. "abc" (substring 0 1)) ; => a
(. " a " trim) ; => a
(.trim " a ") ; => a
(. "abc" substring 0 1) ; => a
(. "abc" (substring 0 1)) ; => a
Member access, ..
The macro named .. is syntactic sugar that allows expressing nested access to
Java object members in a readable way. The effect of using it is the creation of
a cascade of invocations of the . special form discussed above.
In practice, .. performs a series of method calls in which the result of one
becomes the input object for the next. Each expression after .. is
interpreted similarly to the . form, but without the need for manual nesting.
.. macro
(.. " a " trim length) ; => 1
(.. " a " trim length toString (replace "1" "X")) ; => "X"
(.. " a " trim length) ; => 1
(.. " a " trim length toString (replace "1" "X")) ; => "X"
Code organization
In a functional program every construct is an expression that can be computed and returns some value without generating side effects. However, there are classes of problems that, solved in a purely functional way, would produce unreadable or inefficient code. Lisp dialects are therefore tolerant of how algorithms are represented and allow expressing solutions in various ways, offering among other things control structures known from imperative programming languages.
Grouping S-expressions, do
Perhaps the most common construct that lets us momentarily forget that we are
dealing with evaluated expressions and treat program elements as statements is
the do special form. It serves to group multiple expressions in such a way
that only the value of the last one is returned, although side effects
(e.g., displaying text on screen) may occur in all of them.
Usage:
(do & expression...).
The do special form accepts zero or more S-expressions, which will be
evaluated in the order they are given. The returned value will be the result of
evaluating the constant value of the last one.
If no S-expression is given, the returned value will be nil.
do special form
1(do)
2; => nil
3
4(do 123 456)
5; => 456
6
7(do
8 (println "test")
9 123
10 (+ 1 1)
11 (+ 2 2))
12; >> test
13; => 4
(do)
; => nil
(do 123 456)
; => 456
(do
(println "test")
123
(+ 1 1)
(+ 2 2))
; >> test
; => 4
Appending an argument, doto
The doto macro allows appending a given value as the first argument to the
invocations of the given expressions. It is most commonly used to represent
Java method calls in a clear way, or when we want the returned value to be the
value of the first argument of some function, macro, or special form invocation.
(doto value & expression...).
The macro accepts one mandatory argument, which should be an arbitrary value. Each subsequent argument will be treated as an S-expression that, before evaluation, will be transformed so that the given value is substituted in the position of its first invocation argument.
The value returned by the doto macro is the value passed as the first
argument.
doto macro
1(doto 2
2 (println "the first time")
3 (println "the second time"))
4
5; >> 2 the first time
6; >> 2 the second time
7; => 2
8
9(doto (java.util.ArrayList.)
10 (.add 1)
11 (.add 2)
12 (.add 3))
13
14; => [1 2 3]
(doto 2
(println "the first time")
(println "the second time"))
; >> 2 the first time
; >> 2 the second time
; => 2
(doto (java.util.ArrayList.)
(.add 1)
(.add 2)
(.add 3))
; => [1 2 3]
Timing, time
The time macro allows us to display the execution time of a given
expression. It is useful when we want to optimize parts of a program for
performance.
Usage:
(time expression).
The macro’s argument should be an S-expression whose value will be computed.
do can be used if we want to provide more expressions.
The value returned by the time macro is the value of the evaluated expression
that was given.
A side effect of invoking the macro is the display of an execution-time report on standard output.
time macro
1(time 123)
2; >> "Elapsed time: 0.012667 msecs"
3; => 123
4
5(time (Thread/sleep 500))
6; >> "Elapsed time: 505.079375 msecs"
7; => nil
(time 123)
; >> "Elapsed time: 0.012667 msecs"
; => 123
(time (Thread/sleep 500))
; >> "Elapsed time: 505.079375 msecs"
; => nil
Threading, ->
The threading macro, also called the thread-first macro, enables presenting source code with nested invocations in a more readable way. It works by accepting a set of S-expressions and treating each one except the first as a call form (even if it is not enclosed in parentheses), and then inserting in the position of the first argument of each form the value returned by the preceding invocation. Thanks to this we can momentarily forget about Polish notation.
Usage:
(-> expression & expression...).
The macro’s arguments are S-expressions (at least one), and the returned value is the value of the last provided S-expression.
-> macro
1(-> [1 2 3 4] ; result [1 2 3 4]
2 last ; result (last [1 2 3 4]) => 4
3 (- 2) ; result (- 4 2) => 2
4 println ; result (println 2) => nil
5)
6
7; >> 2
(-> [1 2 3 4] ; result [1 2 3 4]
last ; result (last [1 2 3 4]) => 4
(- 2) ; result (- 4 2) => 2
println ; result (println 2) => nil
)
; >> 2
Let us look at the same operations arranged in code without using the macro:
(println
(- (last
[1 2 3 4]))
2)
; => nil
; >> 2
Let us compare both notations in more compact forms:
1(println (- (last [1 2 3 4])) 2) ; from the inside out
2(-> [1 2 3 4] last (- 2) println) ; from left to right
(println (- (last [1 2 3 4])) 2) ; from the inside out
(-> [1 2 3 4] last (- 2) println) ; from left to right
The difference is easy to see: in the first we evaluate values from the most nested to the enclosing ones, and in the second from left to right (with the result substituted each time as the first argument).
Thread-last, ->>
The thread-last macro works similarly to the threading macro, but the value of each preceding S-expression will be substituted not as the first but as the last argument of the next one.
Usage:
(->> expression & expression...).
The macro’s arguments are S-expressions (at least one), and the returned value is the value of the last provided S-expression.
->> macro
1(->> [1 2 3 4] ; result [1 2 3 4]
2 last ; result (last [1 2 3 4]) => 4
3 (- 2) ; result (- 2 4) => -2
4 println ; result (println -2) => nil
5)
6
7; => nil
8; >> -2
(->> [1 2 3 4] ; result [1 2 3 4]
last ; result (last [1 2 3 4]) => 4
(- 2) ; result (- 2 4) => -2
println ; result (println -2) => nil
)
; => nil
; >> -2
In the above example we can see that the difference in computations compared to the previous examples appears in line 3. The subtraction arguments are swapped because the value is substituted as the second argument of the subtraction.
Threading non-nils, some->
The some-> macro works similarly to the -> macro, but threading and further
evaluation of expressions stops immediately when any of them in the chain
returns nil. For this reason the non-nil result threading macro is used where
some form might return an indeterminate value, e.g., when searching collections
or accessing Java methods that, if called with a nil argument, would produce
an exception.
Usage:
(some-> expression & expression...).
The macro’s arguments are S-expressions (at least one), and the returned value
is the value of the last provided S-expression, or nil if the value of any
of them is nil.
some-> macro
1(some-> [1 2 3 4] ; result [1 2 3 4]
2 get 50 ; result (get [1 2 3 4] 50) => nil
3 (+ 2) ; not evaluated
4 println ; not evaluated
5)
6
7; => nil
(some-> [1 2 3 4] ; result [1 2 3 4]
get 50 ; result (get [1 2 3 4] 50) => nil
(+ 2) ; not evaluated
println ; not evaluated
)
; => nil
We can see that in line 2 further evaluation of S-expressions in the chain was
halted because the form (get [1 2 3 4] 50) returned nil (when attempting
to access a nonexistent element at index 50). Let us see what would happen if
we used -> instead of some->:
1(-> [1 2 3 4] ; result [1 2 3 4]
2 get 50 ; result (get [1 2 3 4] 50) => nil
3 (+ 2) ; result (+ nil 2) (exception)
4 println ; not evaluated (exception)
5)
6
7; >> java.lang.NullPointerException:
(-> [1 2 3 4] ; result [1 2 3 4]
get 50 ; result (get [1 2 3 4] 50) => nil
(+ 2) ; result (+ nil 2) (exception)
println ; not evaluated (exception)
)
; >> java.lang.NullPointerException:
Instead of obtaining the indeterminate value nil, the program terminated
abnormally, reporting a Java exception. This was caused by an attempt to sum
nil and the number 2.
Threading non-nils, some->>
The some->> macro works similarly to some->, but the values of previously
evaluated S-expressions are substituted as the last arguments of subsequent
ones.
Usage:
(some->> expression & expression...).
The macro’s arguments are S-expressions (at least one), and the returned value
is the value of the last provided S-expression, or nil if the value of any
of them is nil.
some->> macro
1(some->> [2 4 6 8] ; result [2 4 6 8]
2 (filter odd?) ; result (filter odd? [2 4 6 8]) => ()
3 first ; result (first ()) => nil
4 (+ 2) ; not evaluated
5 println ; not evaluated
6)
7
8; => nil
(some->> [2 4 6 8] ; result [2 4 6 8]
(filter odd?) ; result (filter odd? [2 4 6 8]) => ()
first ; result (first ()) => nil
(+ 2) ; not evaluated
println ; not evaluated
)
; => nil
In line 2 we used the not-yet-discussed function filter. It filters the
collection given as the second argument, and to decide whether an element will
be included in the output data structure or skipped it uses the predicate passed
as the first invocation argument.
Here the role of the predicate is played by the odd? function, which returns
logical truth when the value of its argument is an odd number. As a result,
filter will produce an empty collection because the input contains only even
numbers.
Invoking first on an empty collection returns nil, and at that point
threading ends. Had we not used the some->> macro, the S-expression
(+ 2 nil) would have led to an exception being thrown during evaluation.
Conditional threading, cond->
The cond-> macro works similarly to ->, but S-expressions are interpreted
in pairs. The first of each pair is a conditional expression, and the second
will be evaluated only when the first is truthy (its value is neither false
nor nil). Each second expression of a pair is treated as a call form even if
it is not enclosed in parentheses.
Conditional threading of the first argument is useful for clearly expressing a set of computations that depend on current conditions.
Usage:
(cond-> expression & pair...),
where pair is:
predicate expression.
The cond-> macro accepts an initial expression and pairs of S-expressions,
where the first is a predicate and the second will be evaluated in such a way
that the result of evaluating the previous expression in the chain is inserted
as the first argument. The returned value is the value of the most recently
evaluated S-expression.
cond-> macro
1(def add-one? true)
2(def subtract-one? false)
3
4(cond-> 123 ; result 123
5 add-one? inc ; result (inc 123) => 124
6 subtract-one? dec ; not evaluated
7 true println ; result (println 124) => nil
8)
9
10; => nil
11; >> 124
(def add-one? true)
(def subtract-one? false)
(cond-> 123 ; result 123
add-one? inc ; result (inc 123) => 124
subtract-one? dec ; not evaluated
true println ; result (println 124) => nil
)
; => nil
; >> 124
Conditional threading, cond->>
The conditional thread-last macro works similarly to cond->, but – as the
name suggests – the value of the most recently evaluated S-expression is
substituted in the position of the last argument of the currently evaluated
expression.
Conditional threading of the last argument is useful for clearly expressing transformations performed on collections, since many built-in functions operating on such data structures accept them as their last arguments.
Usage:
(cond->> expression & pair...),
where pair is:
predicate expression.
The cond->> macro accepts an initial expression and pairs of S-expressions,
where the first is a predicate and the second will be evaluated in such a way
that the result of evaluating the previous expression in the chain is inserted
as the last argument. The returned value is the value of the most recently
evaluated S-expression.
cond->> macro
1(def evens? true)
2(def odds? false)
3
4(cond->> [1 2 3 4] ; [1 2 3 4]
5 evens? (filter even?) ; (filter even? [1 2 3 4]) => (2 4)
6 odds? (filter odd?) ; not evaluated
7 true println ; (println '(2 4)) => nil
8)
9
10; => nil
11; >> (2 4)
(def evens? true)
(def odds? false)
(cond->> [1 2 3 4] ; [1 2 3 4]
evens? (filter even?) ; (filter even? [1 2 3 4]) => (2 4)
odds? (filter odd?) ; not evaluated
true println ; (println '(2 4)) => nil
)
; => nil
; >> (2 4)
Binding to a name, as->
The as-> macro serves for threading expression results, but instead of
a fixed position we are dealing with the creation of bindings to a symbolic
name. This is useful in situations where different invocations require placing
the significant argument at different positions.
Usage:
(as-> expression symbolic-name & expression...).
The macro’s arguments are an initial expression whose value will be bound to the symbolic name (given as the second argument), and then threaded through the subsequent S-expressions in such a way that the value of each is bound to the symbolic name before the next one is invoked.
as-> macro
1(as-> [1 2 3 4] result ; after substituting result:
2 (filter even? result) ; (filter even? [1 2 3 4])
3 (last result) ; (last [2 4])
4 [result (inc result)]) ; [4 5]
5
6; => [4 5]
(as-> [1 2 3 4] result ; after substituting result:
(filter even? result) ; (filter even? [1 2 3 4])
(last result) ; (last [2 4])
[result (inc result)]) ; [4 5]
; => [4 5]
Summary
Translating source code
The diagram below presents the individual stages of translating a program’s source code from its textual form into an executable one, including the process of running and obtaining expression values.
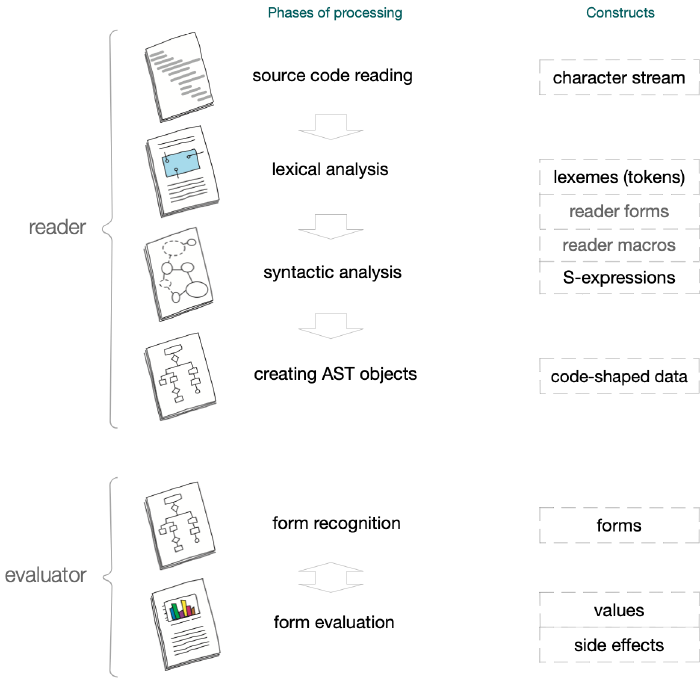
Questions and answers
Let us answer a few questions that will help summarize the introduction to the basic mechanisms present in Lisps (and in Clojure):
-
What is the difference between an S-expression and a list?
An S-expression is a grammatical element of syntax – a symbolic way of organizing source code in a text file. A list, on the other hand, is an in-memory data structure that allows storing data in a nested form while preserving information about the order of occurrence. A list is a good way of representing objects defined by list S-expressions owing to the similarity of arrangement. In Lisp dialects, lists are used to store data expressing list S-expressions of source code in the syntax tree, but they can also be used in programs for operating on utility data.
-
What is the difference between an S-expression and an atom?
An atom is also an S-expression, but a non-compound one. In the abstract syntax tree it will not be represented by a list object, and in the textual form of the program it will not be expressed by elements placed in parentheses.
-
What is the difference between an S-expression and a form?
A form is a syntactically valid S-expression read into memory and converted to known data structures, which is ready for evaluation (computation of its value in the evaluation process).
-
What is the difference between a symbol and a global variable?
A global variable is a
Varobject placed in a map called a namespace that stores a reference to another object (a value). A symbol is aSymbolobject that does not store any reference, but in the same map is used to identify theVarobject (it is the indexing key). One could say that a symbol names a global variable.
See also: